FolderMill can automatically create searchable PDFs out of various files by converting scanned documents into searchable PDF files with text. You can save TIFF, PNG, JPG files, CAD drawings, scans, and other data as searchable PDF files.
We provide a free Optical Character Recognition (OCR) package that can be installed to make FolderMill an OCR application.
How to enable OCR in FolderMill step by step
- Download and install FolderMill 5.0 or newer version (skip this step if you already have it installed);
- Download OCR package from: https://download.fcoder.com/foldermill/foldermill-OCR-package.exe
Install the package and restart the Control Panel; - Create a new Hot Folder and add Convert to PDF Action;
- In the Action settings, check the box next to Make PDF searchable (OCR);
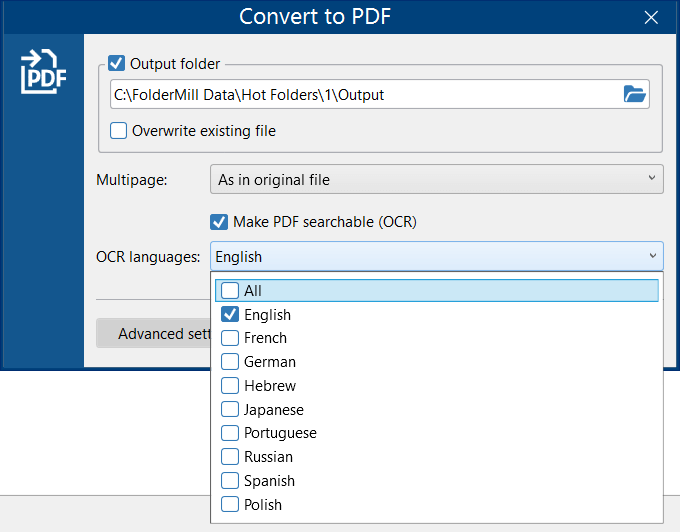
- Check OCR languages and select the language depending on the contents of your source files;

Note: the fewer languages are selected, the better character recognition accuracy will be.
- Click Apply Changes;
- Start FolderMill Processor and copy files to the Source.

Note: the text copied from the resultant PDF may contain typos, errors or random symbols. No OCR software is perfect, so you'll have to check the results – it is necessary to proofread the produced text after OCRing. Still, it's a lot faster than typing the entire document manually. We also suggest reading our tips on how to improve OCR accuracy.
How to use Tesseract or Adobe Acrobat as OCR engine
Tesseract OCR
FolderMill uses Tesseract OCR as its default OCR engine. Tesseract is widely regarded as one of the most accurate OCR engines available, making it a suitable choice for most scenarios. To verify this setting, simply check if it's selected in the Advanced Settings of the Convert to PDF Action, next to OCR engine.
Note: to use the TesseractOCR engine, Windows 10/11 or Windows Server 2016 or newer are required.
Learn more about Tesseract OCR on the official site
Acrobat
If you have Adobe Acrobat installed, you can try switching the OCR processor to Acrobat. This option may provide better results compared to the default optical recognition engine.
To enable Acrobat as OCR processor:
- Open Convert to PDF Action's Advanced settings;
- Set OCR engine to Acrobat;
- Check the Disabled helpers setting and ensure that Acrobat is unchecked;
- Click OK.

Note: you must have Adobe Acrobat DC (Version 12 or higher) installed. The full version is needed, not Acrobat Reader.
OCR languages
FolderMill supports the following OCR languages:
- English
- French
- German
- Hebrew
- Italian
- Japanese
- Dutch
- Portuguese
- Russian
- Spanish
- Polish
- Chinese Simplified
If you would like to have more languages added, please contact us.
How to select pages for OCR
You can choose a specific range of pages for OCR. This can be time-saving when you only want to recognize text from a few pages instead of the entire document.
To select a specific page range, open the Advanced settings of the Convert to PDF Action and adjust the OCR page range.

How to remove noise before OCRing
Source files like scanned documents may contain unwanted elements or distortions. These can include small dots or specks caused by dust, paper texture, or low-quality scanning. Such noise can interfere with OCR software's ability to accurately identify and convert text, resulting in errors.
To enable noise removal in FolderMill before OCR processing, open Convert to PDF's Advanced settings and activate the OCR remove noise option.

Why you may need OCR software
After scanning a document, it becomes an image. Afterwards, you might need to turn printed documents into machine-readable text. The text that you can edit with an editor or copy and paste somewhere. Once the OCR is complete, the text in searchable PDF documents can be selected, copied, or marked up.
DocuFreezer is a simple file converter that can be an alternative OCR solution. You may also like to read:
